Norma SAE JA1011 – Criterios de Evaluación para Procesos de Mantenimiento Centrado en Confiabilidad (RCM)
De acuerdo al diccionario Merriam Webster, una de las definiciones aceptadas para norma es: “algo establecido por la autoridad, la costumbre o el consentimiento general como modelo o ejemplo”. En nuestro caso, una norma se compone de un documento o conjunto de documentos que proporcionan requisitos, especificaciones, directrices o características que se pueden utilizar de forma coherente para garantizar que los materiales, productos, procesos y servicios son adecuados para su propósito. Existen normas internacionales sobre calidad (ISO 9.000), riesgo (ISO 31.000), medio ambiente (ISO 14.000) y gestión de la energía (ISO 50.000) y muchos otros campos que proporcionan información y orientación sobre las prácticas, métodos y procesos diseñados por grupos de expertos internacionales altamente calificados. La mayoría de los profesionales en área técnicas, utilizan normas internacionales para basar su práctica en comprobados métodos matemáticos y / o científicos. Hoy día ya no es aceptado el ensayo y error fuera del laboratorio. Pero, las lecciones aprendidas de su práctica, en conjunto con lamentables incidentes y accidentes de la vida real, proveen el conocimiento sobre los riesgos, su mitigación y, prevención. Muchas de las mejores prácticas y técnicas de gestión de activos y mantenimiento son normas, lo que significa que han sido cuidadosamente definidas y establecidas. La Norma SAE JA1011 sobre Criterios de Evaluación para el Proceso de Mantenimiento Centrado en Confiabilidad (RCM) tiene un trasfondo interesante que incluye historias tanto decepcionantes como exitosas antes de que sus principios fueran concebidos e incorporados eventualmente a un estándar internacional de ingeniería.
La industria de la aviación enfrentó problemas de confiabilidad, seguridad e inefectividad de costos en los años 50. Los regímenes de tareas de mantenimiento basados en el tiempo no fueron capaces de garantizar operaciones sostenibles y la industria de la aviación comercial estaba a punto de sufrir una crisis importante. Los profesionales de mantenimiento y confiabilidad no pudieron encontrar una relación clara entre las horas de tareas programadas y la confiabilidad de los equipos. Además, algunos mantenedores experimentaron que aplicar menos horas de tareas programadas a intervalos de tiempo más largos, dio como resultado una mayor confiabilidad. Las compañías de aviación necesitaban cumplir con ciertos planes de mantenimiento para conservar sus certificaciones de aeronavegabilidad. Casi todas las tareas de mantenimiento recomendadas consistieron en la sustitución o reparación mayor de componentes, antes de que alcanzaran su vida útil expresada en horas de operación. El hecho de que la Administración Federal de Aviación de Estados Unidos (FAA por sus siglas en inglés) negara el permiso para fabricar la aeronave modelo 747 a Boeing, planteó una alarma importante en la industria de la aviación. Se pensó que un avión de mayor tamaño con tres veces la capacidad de pasajeros requeriría mucho más mantenimiento y costos de operación que sus predecesores. Este rechazo del nuevo diseño, junto con un historial de seguridad de casi 60 accidentes por cada 1,000,000 de despegues y altos costos operativos exigió nuevas perspectivas de diseño, operación y mantenimiento de aeronaves que condujeron a la creación del RCM.
Los esfuerzos para comprender los patrones de falla de los componentes no estructurales de los aviones llevaron a Stanley Nowlan y Howard Heap, ambos de United Airlines, a desarrollar un nuevo enfoque hacia el mantenimiento. Documentaron su metodología para el desarrollo de políticas de gestión de consecuencias de fallas en un informe publicado por el Departamento de Defensa de los Estados Unidos en 1978. Su proceso fue llamado Mantenimiento Centrado en Confiabilidad (RCM) y se basó en un procedimiento basado en el sentido común con un diagrama de decisión para la creación de estrategias de mantenimiento para proteger las funciones de los activos. RCM se define como un proceso para determinar qué debe hacerse para mantener los activos físicos funcionando de acuerdo a lo que sus operadores quieren que éstos hagan en su contexto operacional actual. Desde sus orígenes, el RCM ha sido utilizado en muchas industrias y en casi todos los países industrializados en el mundo. Ha habido muchas interpretaciones individuales del informe de Nowlan y Heap que condujeron a la creación de una variedad de métodos que difieren ampliamente del proceso original.
El propósito de la norma SAE JA1011, publicada en 1999, es establecer los criterios que cualquier proceso debe cumplir para ser llamado “RCM”. El documento de doce páginas, revisado en agosto de 2009, describe los requerimientos mínimos para que un proceso se considere un método en conformidad con RCM. La norma proporciona los criterios para establecer si un proceso dado sigue los credos de RCM como se propuso originalmente. También puede servir como una guía para las organizaciones que buscan capacitación, facilitación y consultoría de RCM.
La norma SAE JA1011, de AGO 2009, establece que para que un proceso sea reconocido como RCM debe seguir los siete pasos en el orden que se muestra a continuación:
- Delimitar el contexto operativo, las funciones y los estándares de desempeño deseados asociados al activo (contexto operacional y funciones).
- Determinar cómo un activo puede fallar en el cumplimiento de sus funciones (fallas funcionales).
- Definir las causas de cada falla funcional (modos de falla).
- Describir qué sucede cuando ocurre cada falla (efectos de falla).
- Clasificar los efectos de las fallas (consecuencias de la falla).
- Determinar qué se debe realizar para predecir o prevenir cada falla (tareas e intervalos de tareas).
- Decidir si otras estrategias de gestión de fallas pueden ser más efectivas (cambios de una sola vez).
El Contexto Operacional y las Funciones
El primer paso para aplicar RCM a un activo físico implica definir su contexto operacional y las funciones requeridas bajo él. El punto de partida lógico para diseñar una estrategia de gestión de mantenimiento o fallas (o una política de gestión de activos como lo llama la norma) es entender claramente lo que se quiere del activo. Esto representa un cambio de perspectiva para los mantenedores. A menudo, el departamento de mantenimiento no está involucrado en la determinación de por qué un activo en particular está realmente allí. Si queremos mantener el rendimiento de funciones específicas, necesitamos saber exactamente cuáles son las funciones, así como los parámetros operativos que definen los niveles de rendimiento necesarios para satisfacer la demanda operativa.
Para definir correctamente el contexto operacional, el equipo de RCM debe describir las funciones, siguiendo esta estructura, de acuerdo con la norma:
- Las condiciones en las que se prevé que funcionará un activo físico o un sistema deben estar definidas, registradas y estar disponibles.
- Deben ser identificadas todas las funciones primarias y secundarias del activo / sistema.
- Todas las declaraciones de funciones deben contener un verbo, un objeto y un estándar de desempeño cuantitativo (siempre que sea posible).
- Los estándares de desempeño utilizados en la declaración de funciones serán el nivel de desempeño deseado por el usuario del activo en su contexto operacional actual. La capacidad de diseño no debe ser utilizada en la declaración de función.
Fallas Funcionales
Una falla funcional se define como “un estado en el cual un activo físico o sistema no es capaz de ejercer una función específica a un nivel de desempeño deseado”. Es fundamental tener una comprensión perfecta de las funciones de los activos y el nivel de rendimiento deseado para determinar las fallas. Podría haber fallas funcionales totales o parciales. Esto significa que el activo puede no ser capaz de cumplir una función en particular o que puede realizarla a un nivel de desempeño inferior al deseado. La norma SAE requiere que se identifiquen todos los estados de fallas asociados con cada función para que podamos identificar todas las causas relevantes.
Modos de falla
Un modo de falla es un evento único, que provoca una falla funcional y cada modo de falla normalmente tiene una o más causas. Por lo tanto, necesitamos una tormenta de ideas sobre todas las posibles causas de eventos que afectan la capacidad de los activos para realizar cada función específica, a los niveles deseados de rendimiento. La norma recomienda no ser demasiado superficial en el nivel de causalidad de los modos de falla. Cuando se enumeren los modos de falla considerar:
- Deben ser identificados todos los modos de falla razonablemente propensos a causar cada falla funcional.
- El método utilizado para decidir qué constituye un modo de falla “razonablemente propenso o probable” debe ser aceptable para el propietario o usuario del activo. Generalmente se utiliza el consenso para decidir qué modos de falla analizar y cuáles descartar.
- El nivel de causalidad para los modos de falla debe ser suficientemente exhaustivo para que – puedan asignárseles políticas de gestión de fallos.
- Los modos de falla enumerados en el análisis deben considerar los eventos que han ocurrido antes, los modos de falla que se previenen en las tareas programadas existentes y otros eventos que es probable que se produzcan en el contexto operacional real, pero que nunca ha ocurrido.
- Los errores humanos y de diseño que causan un evento de falla deben incluirse en la lista de modos de falla, a menos que estén siendo abordados por otros métodos de análisis.
Efectos de Falla
Los efectos de falla cuantifican el “daño” que cada evento en particular puede causar a la planta o a la organización. Se recomienda describir “lo que ocurre cuando se produce el modo de falla”. La norma recomienda varias consideraciones relevantes para ayudar a entender que tan grave pudiera ser cada causa de falla particular. Los efectos de falla ayudan a determinar hasta qué punto cada modo de falla es relevante teniendo en cuenta lo siguiente:
- ¿Hay alguna evidencia de que ha ocurrido la falla?
- ¿Cuál es el impacto potencial que tiene la falla en la seguridad del personal?
- ¿Cuál es el impacto potencial que tiene la falla en el medio ambiente?
- ¿Cómo se ve afectada la producción o las operaciones?
- ¿Hay algún daño físico causado por la falla?
- ¿Hay algo que deba hacerse para restaurar la función del sistema después de la falla?
Consecuencias de la Falla
Los efectos de fallas se clasifican en categorías basadas en la evidencia que se tiene de éstas, impacto en la seguridad, en el medio ambiente, en la capacidad operacional y los costos. Deberíamos ser capaces de decidir cuál de las cuatro categorías se aplican a cada efecto de modo de falla. Se debe elegir sólo una categoría, la que sea más grave. Los modos de falla ocultos y evidentes deben estar claramente separados. Las fallas con impacto en la seguridad o en el medio ambiente deben distinguirse de los que sólo tienen repercusiones económicas, ya sea por consecuencias operacionales o no operacionales. Como cada paso dentro del proceso de RCM, la determinación de la consecuencia del fallo es fundamental. Las estrategias de mantenimiento se seleccionan cuidadosamente para cada causa de falla crítica basada en un procedimiento de decisión que utiliza la consecuencia como punto de partida.
Selección de Estrategias de Mantenimiento
El patrón predominante de cada falla identificada debe ser tomado en cuenta al momento de recomendar cualquier estrategia de gestión. Los modos de fallas pueden ocurrir por tiempo de uso o edad o de forma aleatoria. También pueden ocurrir prematuramente o siguiendo un patrón de desgaste, después de algún tiempo significativo de operación. Se debe tener cuidado en recomendar tareas de mantenimiento basadas en patrones predominantes reales de falla. La norma SAE JA1011 reconoce 5 posibles estrategias de mantenimiento que deben ser aplicadas para mitigar las consecuencias de cualquier falla. Estas son las siguientes:
- Tareas de mantenimiento basadas en condición – Estas tareas están destinadas a detectar fallas potenciales. Tal detección debe ocurrir con suficiente antelación para que la acción correctiva se pueda tomar antes de un paro operacional. Una tarea de monitoreo de condición es aplicada a intervalos fijos para predecir la tendencia de un paro operacional antes de que ocurra una falla funcional.
- Tareas de reparaciones programadas – Las tareas de reparación basadas en el tiempo deben ser realizadas en función de la vida útil del activo. Es decir, el momento en que la tasa de falla del equipo deja de ser constante. En teoría, al final de la vida útil, la tasa de falla del activo aumenta más allá de lo que podemos tolerar. Además de la vida útil, el costo de la reparación preventiva también necesita ser evaluado. Esto es, una comparación del costo del trabajo de reparación contra el de las consecuencias de la falla funcional debe confirmar la viabilidad económica de la tarea.
- Tareas de reemplazo programado – Las tareas programadas de descarte y reemplazo se consideran cuando se demuestra que es más rentable reemplazar que reparar el activo. Se recomienda aplicar dicha sustitución al final de la llamada vida “útil” del mismo.
- Tareas de búsqueda de fallas– Estas tareas están destinadas a detectar fallas ocultas asociadas, la mayoría de las veces, con dispositivos de protección o componentes redundantes. Debemos asegurarnos de que es físicamente posible realizar la tarea de búsqueda recomendada y que la frecuencia sugerida es aceptable para el propietario del activo. En el libro se hablará más sobre la frecuencia de la tarea.
- Tareas de rediseño– A veces no se pueden encontrar tareas de búsquedas de fallas ni basadas en tiempo o condición adecuadas para aplicarse a un modo de falla crítico. Entonces, puede ser imperativo que las modificaciones (también llamadas “cambios de una sola vez”) se implementen con el fin de abordar adecuadamente las consecuencias de la falla. Los cambios en la configuración física de los activos, los procedimientos de operación o mantenimiento, el adiestramiento del operador / mantenedor y la alteración del contexto operacional son todas las formas posibles de cambios de una sola vez o rediseño potencialmente necesario para la mitigación de fallas.
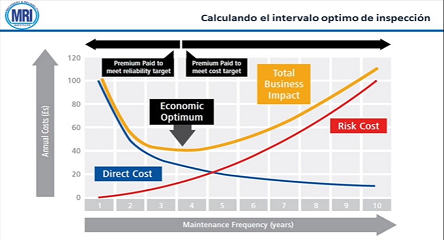
Cuando se establecen las tareas de mantenimiento, deben ser asignadas las frecuencias adecuadas a fin de que los efectos de falla sean abordados eficazmente. Algunas fórmulas matemáticas y estadísticas se utilizan para apoyar la decisión del intervalo de la tarea. En tal caso, la norma SAE JA1011 recomienda que la matemática utilizada sea aceptable para el propietario del activo. Asimismo, se debe tener cuidado al recomendar nuevas tareas de mantenimiento ya que el proceso de RCM no puede, de ninguna manera, reemplazar las leyes, reglamentos y / u obligaciones contractuales existentes. Por lo tanto, es aconsejable que un auditor interno experto en la materia evalúe y acepte recomendaciones hechas como parte del proceso de RCM. La norma SAE JA1011 RCM es bastante directa y concisa, al establecer los criterios para identificar los procesos de análisis no conformes. Es particularmente útil para las personas que desean obtener servicios de RCM (entrenamiento, análisis, facilidades, consultoría, etc.). La implementación exitosa de RCM requiere de grupos multidisciplinarios entrenados para aplicar el proceso con la guía de un facilitador certificado que domine su ejecución. Los objetivos principales del RCM implican tareas periódicas de mantenimiento optimas, procedimientos de mantenimiento y operación reestructurados, rediseño de componentes de la máquina rediseñados, etc. Las implementaciones exitosas reportan una reducción significativa en la aplicación de horas-hombre de tareas programadas, un mejor desempeño de seguridad y mayor confiabilidad y disponibilidad de activos, lo que resulta en un rendimiento financiero significativo. Cuando se aplica correctamente, el objetivo del esfuerzo del RCM es proteger las funciones de los activos para reducir el riesgo o los efectos de fallas a niveles aceptables de acuerdo a las expectativas de su propietario.