Concepto
Existe en el ámbito de Mantenimiento una tendencia a pasar por alto, o al menos no atribuirle la importancia que tiene, al concepto de Modo de Falla. Encontramos, durante nuestras aplicaciones de RCM (Reliability Centered Maintenance) y PMO (Planned Maintenance Optimizing), que además se confunde su significado con el de Falla Funcional.
La norma SAE JA-1011, que establece los criterios mínimos para que un proceso pueda calificar como RCM, define los términos claramente en su punto 3 (Definitions). Lo que sigue es una traducción libre de él:
· Modo de Falla: Un evento que por sí solo ocasiona una falla funcional
· Falla Funcional: Un estado en el que un activo físico o sistema es incapaz de cumplir una función específica en un nivel de desempeño deseado
Por ejemplo, la Falla Funcional “El motor no arranca” podría tener un Modo de Falla que fuera “Desgaste normal de las escobillas”
En el punto 5.3.3 la norma indica que el Modo de Falla debe identificarse a un nivel de causa tal que se pueda hallar alguna política de manejo apropiada. El Modo de Falla, por lo tanto, no necesariamente es la causa raíz de una falla funcional sino un evento en la cadena de causas y efectos sobre el que se pueda actuar efectivamente, rompiéndola.
O, dicho con otras palabras, el Modo de Falla es una causa accionable. Ocurre que la causa raíz (o las causas raíz) no siempre es asequible, o que su eliminación resulta en una relación costo-beneficio desfavorable, por lo que no hay en esos casos otra solución más que sacrificar el mayor abanico de ventajas que daría actuar sobre aquélla y hacerlo aguas abajo en la cadena de sucesos. Debe destacarse que, por lo general, el llegar a la causa raíz y eliminarla ofrecería beneficios colaterales que se perderían en caso de no hacerlo.
Retomando el caso de las escobillas, éstas podrían haberse gastado prematuramente por causa de su material constituyente, que difiriese del original. La causa raíz es sin duda “Material de las escobillas inadecuado”, pero si no fuera posible cambiar la provisión, por la causa que fuere, no sería aquélla una causa accionable y deberíamos volver a “Desgaste normal de las escobillas”. Obviamente el tiempo medio a la falla (MTTF) en este nuevo estado “normal” resultaría menor, y el costo del mantenimiento se incrementaría tanto por el mayor consumo de escobillas cuanto por el de otros recursos de mantenimiento (en general escasos). Muy probablemente se experimentaría también una pérdida de throughput, que podría impactar en el beneficio mucho más fuertemente que los aumentos de costos. Todos estos valores diferenciales se anularían si la auténtica causa raíz podría ser atacada.
Importancia de su inclusión en los registros históricos
La experiencia del personal de Mantenimiento en primer lugar, y la historia de los eventos pasados, son los recursos más importantes de los que se dispone a la hora diseñar un plan de mantenimiento. Ya sea que se emplee un proceso formal como FMEA (Failure Mode and Effects Analysis), o los mencionados RCM o PMO, o que se lo haga informalmente, es finalmente el conocimiento de los equipos específicos o de otros similares, o el de sus componentes análogos, el que guía la elaboración de las políticas que finalmente se aplicarán.
Pero, salvo casos de memoriosos excepcionales, nuestra capacidad de retener mentalmente eventos en forma detallada junto con sus fechas de ocurrencia es pobre, lo que se agrava por la inmediatez de respuestas requeridas en las sesiones grupales de definición de políticas de mantenimiento en aras de la eficiencia.
Más aún, vemos que esas estimaciones prueban ser incorrectas en una proporción de casos importantes cuando a posteriori se consigue disponer, por algún otro medio, de la información exacta. En su libro “Why we make mistakes”, Joseph Hallinan describe cómo en realidad “no estamos cableados como creemos estarlo”, cuestión que nos hace “funcionar” de manera diferente a como creemos que lo haríamos en determinadas circunstancias. Algunos de los casos citados se corresponden totalmente con nuestras observaciones en grupos participativos de generación de políticas de mantenimiento.
Lo antedicho apoya la necesidad de disponer de registros históricos de eventos que sean veraces, completos, inteligibles y de fácil hallazgo.
Pero, ¿qué es lo que buscamos y que deba hallarse fácilmente? El Modo de Falla
Un registro histórico que no contenga el Modo de Falla causante de una Falla Funcional claramente definido es inútil a los fines de ser usufructuado. Es sobre el Modo de Falla que deberemos actuar para predecirlo, evitar su ocurrencia, o mitigar sus efectos.
El Modo de Falla debería ser un campo clave de cualquier registro histórico. Como todo campo clave de una base de datos, debe estar codificado. Esta característica permite no solamente simplificar las búsquedas sino evitar que se designe de diferentes maneras modos de falla idénticos o, por el contrario, que se empleen nombres idénticos para modos de falla que en realidad son distintos.
Un Modo de Falla correctamente escrito debe incluir la pieza o componente que falla, la causa accionable claramente descripta, y además su mecanismo, es decir el proceso que llevó al modo de falla. Para las escobillas tomadas como ejemplo, no basta con indicar que “Desgaste de las escobillas” es el Modo de Falla. Debe describirse el mecanismo que produjo el desgaste de manera que se puedan adoptar, basándose en él (entre otros factores), las políticas de mantenimiento para eliminar o mitigar su efecto. Las tareas propuestas no serían las mismas si el Modo de Falla fuese “Desgaste de las escobillas normal” que si se hubiese descripto como “Desgaste de las escobillas por excesiva tensión de los resortes luego de un cambio”.
Necesidad de disponer de una estructura de los activos
Dado que la mayoría de los activos son complejos y que se hallan extendidos físicamente, resulta impráctico asociar los modos de falla a aquéllos como un todo, soliéndose hacerlo a sus subconjuntos. Éstos son los que se suelen denominar Sub-unidades, Objetos Técnicos o Ítems Mantenibles, siendo esta última la designación que más claramente transmite la idea. De no hacerlo así, obligaría a escribir a cada modo de falla de una manera muy extensa y haría su búsqueda posterior más complicada. En el caso de las escobillas del motor de arranque, el modo de falla sería “Desgaste normal de las escobillas del motor de arranque” para distinguirlas de, por ejemplo, las del generador.
La existencia de una estructura de los activos, también llamada de árbol, es así un prerrequisito para poder planificar y programar actividades de mantenimiento fundadas en experiencias comprobables objetivamente. Y, luego de implementadas, para verificar su eficacia y permitir su eventual corrección, completando así el Círculo de Deming.
Es muy esclarecedora como modelo a seguir para establecer las estructura de los activos físicos en cada industria en particular, el que propone la norma ISO 14224 para los equipos de la industria del petróleo.
Ella tiene el propósito de proveer una base completa para la recolección, de manera estándar, de datos de confiabilidad y mantenimiento en diferentes áreas de la industria del petróleo, permitiendo compartir conocimientos y experiencia entre las diferentes compañías.
Cada industria debe desarrollar su propia estructura basándose no solamente en sus equipos específicos sino en sus criterios generales de mantenimiento.
La definición de Modo de Falla de la ISO 14224 difiere sensiblemente de la de SAE JA1011, por lo que advertimos a los lectores sobre el particular. ISO 14224 denomina Modo de Falla a “la manera en que se observa la falla” (lo que representa la Falla Funcional para SAE JA1011), en tanto que el Modo de Falla definida por esta última es lo que la primera designa como Descriptor y Causa de la Falla.
Perfeccionamiento de los Modos de Falla
La distinción entre Descriptor y Causa de la Falla en el registro pone en evidencia una realidad que habitualmente se soslaya por razones de simplicidad de los registros.
Cuando el técnico de mantenimiento registra un modo de falla, completando el campo “Descriptor”, lo hace empleando su experiencia y con los mejores datos que posee al momento de darse la falla. Sin embargo, es posible que el auténtico modo de falla resulte, luego de un análisis más profundo, diferente, ya sea porque haya una causa accionable más profunda, o porque sencillamente su análisis original resultare incorrecto. En tal caso, la causa resultante definitiva quedaría asentada en el campo “Causa”. Esta distinción no se observa habitualmente en la práctica industrial, limitándose en el mejor de los casos en que se haga un análisis posterior, a un solo campo de Modo de Falla que se corrige en esa eventual segunda instancia, “pisándose” la información original.
Nuestra experiencia indica que se requiere de un seguimiento diario de los registros por parte de la supervisión para asegurar que los otros atributos (veracidad, integridad y claridad) se mantengan, de lo contrario a la hora de requerirlos, los registros serán poco confiables, confusos, y por ende poco útiles. La supervisión, que debe estar entrenada en la tarea y valorizarla en su real magnitud, debe actuar proactivamente con vistas al uso futuro de la información, haciendo preguntas y corrigiendo lo que considere necesario.
Pero fundamentalmente esta gestión permite corregir errores de criterio al determinar las causas y descubrir la eventual existencia de otras más profundas, vinculadas al comportamiento de las personas o a cuestiones latentes, vinculadas a procedimientos, creencias, paradigmas instalados, etc., permitiendo realizar las correcciones necesarias a tiempo, cuando la experiencia del evento aún esté “fresca” y con la participación de los involucrados.
Como lo expresa la norma ISO 14224, “la recolección de datos es una inversión”. Si no se la mantiene, no rendirá sus frutos y finalmente se deteriorará.

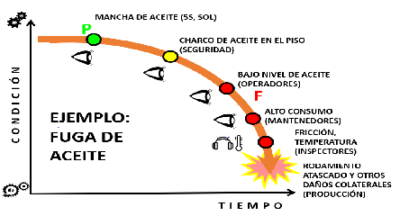

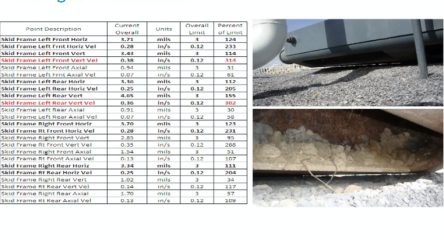


Podría publicar un caso de estudio completo sobre cómo dectectar modo de fallo?
Buenas Tardes Claude,
Claro que sí. Ahorita mismo nos comunicaremos con usted,
Saludos!